Jupyter-Notebooks
erfreuen sich in den Datenwissenschaften wachsender Beliebtheit und wurden zum
De-facto-Standard für schnelles Prototyping und explorative Analysen. Sie
beflügeln nicht nur Experimente und Innovationen enorm, sie machen auch den
gesamten Forschungsprozess schneller und zuverlässiger.
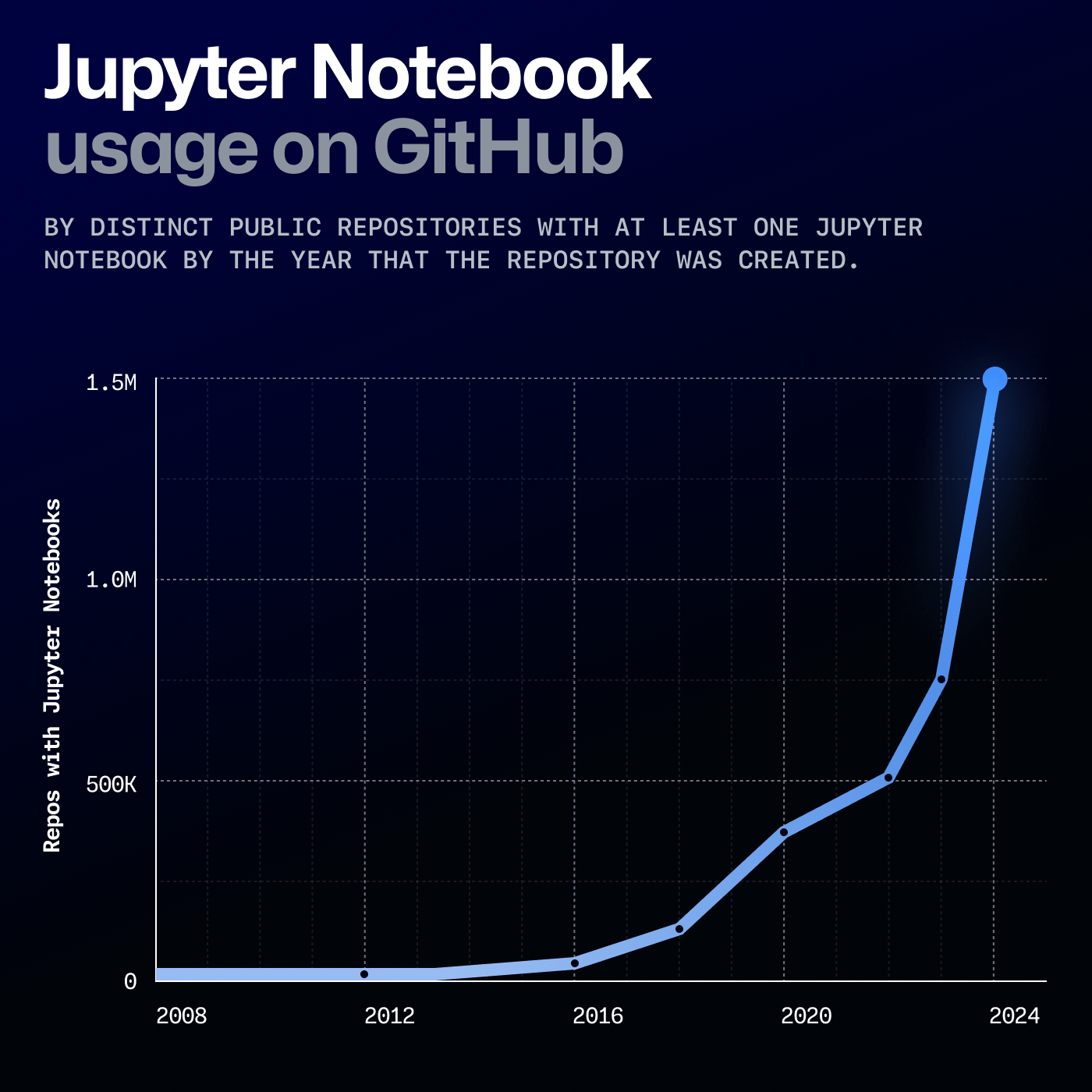
„Der sprunghafte Anstieg der Nutzung von Jupyter Notebooks zeigt, dass
Open Source eine wachsende Gemeinschaft unterstreicht, insbesondere da
Python zur meistgenutzten Sprache … aufsteigt. Seit 2018 hat die Nutzung von
Jupyter Notebooks stetig zugenommen – und dieses Wachstum stieg im Jahr 2022
sprunghaft an, als die Forschung und das Experimentieren mit generativer KI
und maschinellem Lernen Fahrt aufnahmen. Seit 2022 ist die Nutzung von
Jupyter Notebooks auf GitHub um mehr als 170 % angestiegen. Und seit dem
letzten Jahr ist die Nutzung um 92 % gestiegen. Datenwissenschaftler*innen
und Forschende im Bereich maschinelles Lernen nutzen die
Open-Source-Anwendung häufig für maschinelles Lernen, Datenvisualisierung
und mehr.“